Golang Memory Management: Stack vs. Heap
Go uses two types of memory for storing values: the stack and the heap.
The Stack
- Each goroutine has its own initialized stack.
- It provides fast access and automatic memory management (cleaning).
The Heap
- Any value on the heap is managed by the Garbage Collector (GC).
- The Go GC uses a concurrent mark-and-sweep algorithm, which can sometimes introduce latency.
Memory Allocation: new vs. make
new: Allocates a single block of memory and returns a pointer to newly allocated, zeroed memory. It is mostly used for struct types.make: Used to initialize slices, maps, and channels. It allocates and initializes these data structures.
Use Case 1: Stack Allocation (No Pointers)
package main
func main() {
n := 4
n2 := square(n)
println(n2)
}
func square(n int) int {
return n * n
}
func println(_ int) {
}
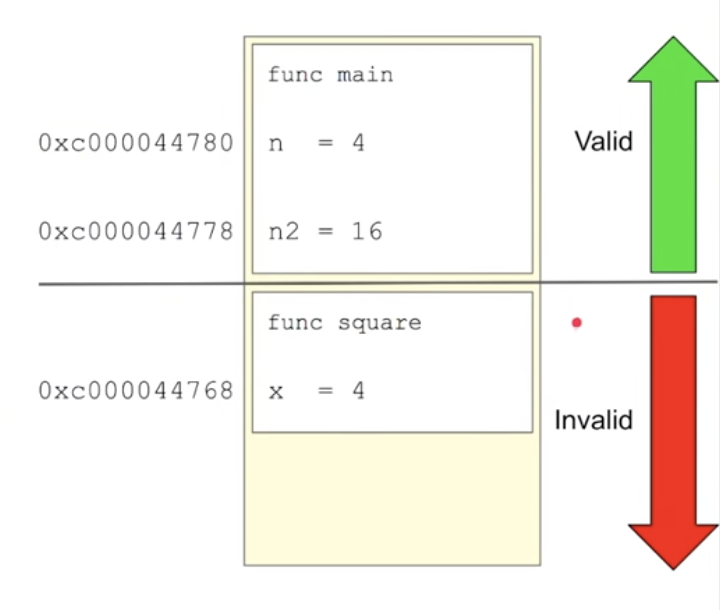
In this scenario:
- Stack Frame 1: Created for
main. - Stack Frame 2: Created for
square.
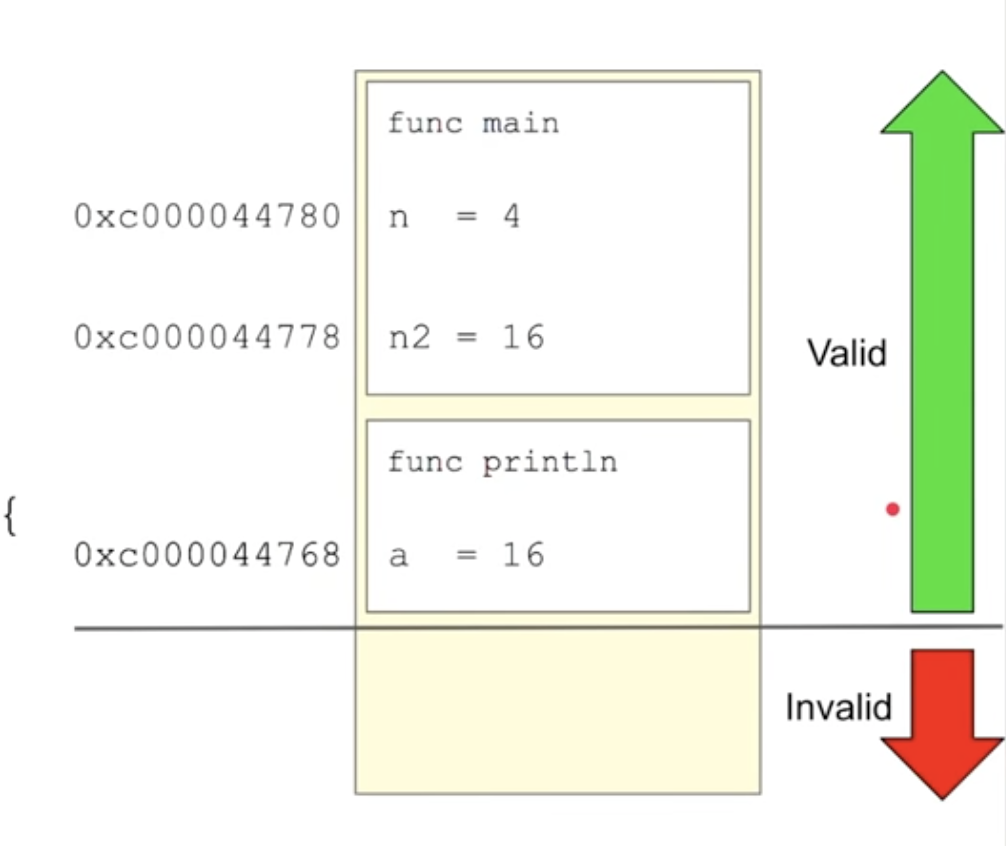
Once the square function finishes its calculation, Go does not immediately “clear” the stack frame. The value of n remains part of the square stack frame, but the frame is marked as invalid. When println is called, its stack frame replaces the now-invalid square stack frame—a process known as self-cleaning.
Use Case 2: Pointers and the Stack
package main
func main() {
n := 4
square(&n)
println(n)
}
func square(n *int) int {
return *n * *n
}
func println(_ int) {
}
Running escape analysis (go build -gcflags="-m -l" test.go) shows:
./test.go:9:13: n does not escape
In this case, n stays on the stack. The square function receives a pointer that points to the value of n in the main stack frame. Generally, passing a pointer “down” a call stack allows the value to remain on the stack.
Use Case 3: Returning a Pointer (Escaping to the Heap)
package main
func main() {
n := 4
n1 := square(&n)
println(*n1)
}
func square(x *int) *int {
y := *x * *x
return &y
}
func println(_ int) {
}
Escape analysis shows:
./test.go:10:2: moved to heap: y
When square returns a pointer to a local variable y, the Go compiler recognizes that y must outlive the square stack frame. To ensure println can access the value, Go allocates y on the heap. This is called “sharing up,” and it typically causes a value to escape to the heap.
Deep Dive into Memory Allocation
The compiler decides whether a value is allocated on the heap or the stack. Common reasons for heap allocation include:
- A value is referenced after the function that created it returns.
- The compiler determines a value is too large for the stack.
- The compiler cannot determine the size of a value at compile time.
Example: The io.Reader Interface
The design of the io.Reader interface reflects these efficiency considerations:
type Reader interface {
Read(b []byte) (n int, err error)
}
If it were designed to return a slice instead:
type Reader interface {
Read(n int) (b []byte, err error)
}
Every call to Read would likely result in a heap allocation for the returned slice, leading to significant garbage collection overhead. By having the caller provide the buffer, Go can often keep that memory on the stack.